
-
Some advanced indexing techniques
-
Make computed columns and create index on these
I am sure most of us have written application codes where you select a result set from the database and for each row do a calculation in the result set to produce the information to show in the output. Sometimes this processing can be done directly in the database. You can specify a database column as a Computed column by specifying a formula. While your TSQL includes the computed column in the select list, the SQL engine will apply the formula to derive the value for this column. So, when executing the query, you will get the result for the computed column.
But sometimes this might be expensive if the table contains large number of rows. And this might get even worse if the computed column is specified in the WHERE clause in a SELECT statement because in this case the database engine has to calculate computed column's value for each row in the table. To improve performance, you need to create index on the computed columns as in this case SQL Server calculates the result in advance and builds an index over them. Additionally, when the corresponding column values are updated (That the computed column depends on), the index values on computed column are also updated. And so while executing the query, the database engine does not have to execute the computation formula for every row in the result set.
-
Create Indexed Views
The Views are nothing but compiled SELECTs. Views does not remember the result they were built upon. They are just compiled queries. BUT! Why not to apply indexes on Views and so they to become Indexed Views? For an Indexed View, the database engine processes the SQL and stores the result in the data file just like a clustered table and SQL Server will automatically maintain the index when data in the table will change. As a result, when you will do a SELECT query on the Indexed View, the DB engine will select the values from and index which obviously performs very fast.
But there are some restrictions:
- The View has to be created with SCHEMABINDING option. In this case, the DB engine will not allow you to change the underlying table schema.
- The View can't contain any nondeterministic function, DISTINCT clause and subquery.
- The underlying tables in the View must have clustered index (Primary keys)
-
Create indexes on User Defined Functions
But this is not something really easy. You will have to create a computed column specifying an UDF as the formula and then you will have to create index on the computed column field. The steps are:
-
Create the function (if it does not exists already) and make sure that this function is deterministic. Add SCHEMABINDING option in the function definition. Example:
CREATE FUNCTION [dbo.ufnGetLineTotal]
(
-- Add the parameters for the function here
@UnitPrice [money],
@UnitPriceDiscount [money],
@OrderQty [smallint]
)
RETURNS money
WITH SCHEMABINDING
AS
BEGIN
return (((@UnitPrice*((1.0)-@UnitPriceDiscount))*@OrderQty))
END - Add a computed column in your desired table and specify the function with parameters as the value of the computed column.
- Create an index on the computed column.
Creating indexes on UDFs will give you a tremendous performance benefit when you include the UDF in a query, especially if you use UDFs in the join conditions between different tables/views.
-
Create the function (if it does not exists already) and make sure that this function is deterministic. Add SCHEMABINDING option in the function definition. Example:
-
Create indexes on XML columns
XML columns are stored as BLOBs in SQL Server 2005 and later which can be queried using XQuery, but querying XML data types can be very time consuming without an index. The syntax to create Primary XML indexes is:
CREATE PRIMARY XML INDEX index_name ON <object> ( xml_column )
When it is created, SQL Server shreds the XML content and creates several rows of data that include information like element and attribute names, the path to the root, node types and values, and so on. So, creating the primary index enable the SQL server to support XQuery requests more easily.
Primary indexes are good, but SQL Server still needs to scan through the shredded data to find the desired result. Here come to help Secondary XML indexes:
CREATE XML INDEX
index_name
ON <object> ( xml_column )
USING XML INDEX primary_xml_index_name
FOR { VALUE | PATH | PROPERTY }
As seen from the syntax, there are 3 types of them:
- Path Secondary XML indexes: useful when using the .exist() methods to determine whether a specific path exists.
- Value Secondary XML indexes: used when performing value-based queries where the full path is unknown or includes wildcards.
- Property Secondary XML indexes: used to retrieve property values when the path to the value is known.
-
Make computed columns and create index on these
-
Apply de-normalizations, use history tables and pre-calculated columns
-
De-normalization
As written in one of the previous posts, normalization is good, but sometimes having some level of de-normalization is good because the reporting and data analytical queries would run very fast. So, when we have a query with JOINs for example just to get the value of one field that is not in the base table and the query performs bad, we may want to to duplicate that field with it's values in the base table. Yes, we will add redundancy, but because we will not have to do the JOINs the resulting query most probably will run faster and we will get better performance. But remember that de-normalization is a trade-off between data redundancy and select operation's performance. So use this carefully and only after applying all other optimizations if still needed.
-
History tables
If in your application you have some data retrieval operations, for example reporting, that periodically runs on a time period and if the process involves tables that are large in size having normalized structure, you can consider moving data periodically from your transactional normalized tables into a de-normalized heavily indexed single history table. Also you can create a scheduled operation in your database server that would populate this history table on a specified time on given periods. So, the periodic data retrieval operation than has to read data, will do it only from a single table that is heavily indexed and the operation would perform a lot faster.
-
Creating the scheduled operation
Here are the steps to create a scheduled operation in SQL Server that periodically populates a history table on a specified schedule.
-
Make sure that SQL Server Agent is running. To do this, launch the SQL Server Configuration Manager, click on the SQL Server 2005 Services and start the SQL Server Agent by right clicking on it.
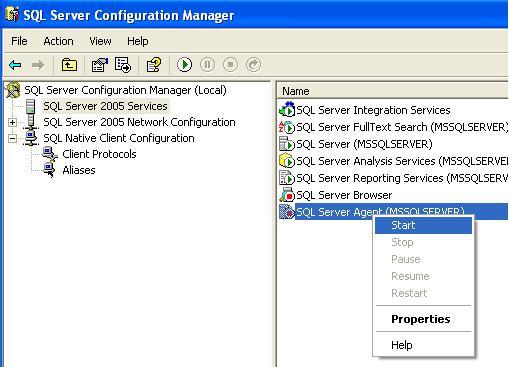
-
Expand SQL Server Agent node in the object explorer and click on the Job node to create a new job. In the General tab, provide job name and descriptions.
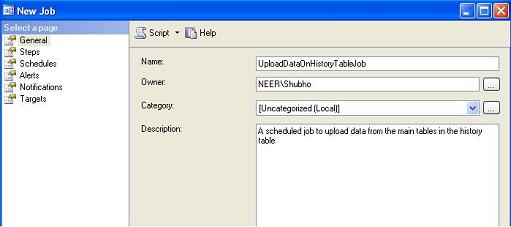
-
On the Steps tab, click on the New button to create a new job step. Provide a name for the step and also provide TSQL, that would load the history table with the daily sales data, along with providing Type as Transact-SQL script(T-SQL). Press OK to save the Step.
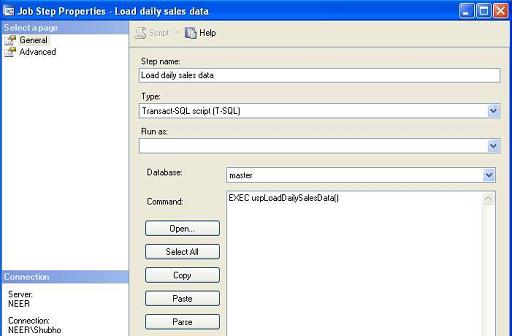
-
Go to the Schedule tab and click on New button to specify a job schedule.
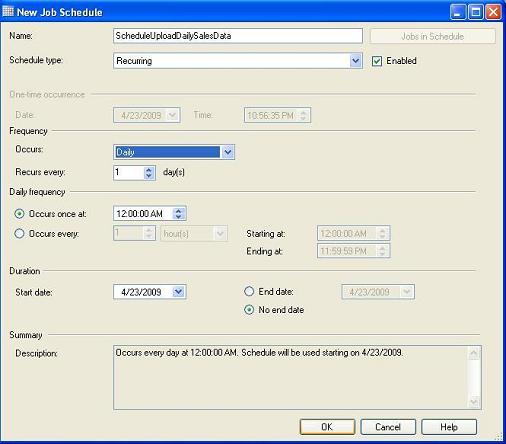
- Click the OK button to save the schedule and also to apply the schedule on the specified job.
-
Make sure that SQL Server Agent is running. To do this, launch the SQL Server Configuration Manager, click on the SQL Server 2005 Services and start the SQL Server Agent by right clicking on it.
-
Perform expensive calculations in advance in data INSERT/UPDATE, simplify SELECT query
In most of the cases in your application you will see that data insert/update operations occur one by one, for each record. But, data retrieval/read operations involve multiple records at a time. So, if you have a slowly running read operation (select query) that has to do complex calculations to determine a resultant value for each row in the big result set, you can consider doing the following:
- Create an additional column in a table that will contain the calculated value.
- Create a trigger for Insert/Update events on this table and calculate the value there using the same calculation logic that was in the select query earlier. After calculation, update the newly added column value with the calculated value.
- Replace the existing calculation logic from your select query with the newly created field.
After doing this, the Insert/Update operation for each record in the table will be a bit slower because the trigger will now be executed to calculate a resultant value, but the data retrieval operation should run faster than previous. Because while the SELECT query executes, the database engine does not have to process the expensive calculation logic any more for each row.
-
Creating the scheduled operation
-
De-normalization
Posted At : Jan 06, 2010 14:10 PM
| Posted By : Ed Tabara
Related Categories: SQL
Related Categories: SQL
| 4374 Views
| 5% / 0% Popularity
Comments